共识机制
概述#
我们提出了一种基于部分同步假设情形下的并行拜占庭容错协议 CBFT(Concurrent Byzantine Fault Tolerance),解决区块链共识效率的问题。本文分析了 PBFT,Tendermint,Hotstuff 等共识协议,CBFT 综合了其优点,通过 pipeline 的方式完成区块生成和确认的并行,在一个视图窗口内可以出多个块,并可以在$O(n^2)$内完成视图窗口切换,从而提高共识效率。
分布式网络模型#
按照分布式系统理论,分布式系统的网络模型分为三类:
同步网络模型:节点所发出的消息,在一个确定的时间内,肯定会到达目标节点
异步网络模型:节点所发出的消息,不能确定一定会到达目标节点
部分同步网络模型:节点发出的消息,虽然会有延迟,但是最终会到达目标节点
同步网络模型是十分理想的情况,异步网络模型是更为贴近实际的模型,但据FLP 不可能[1]原理,在异步网络模型假定下,共识算法不可能同时满足安全性(safety)和活跃性(liveness),目前的 BFT 类共识算法多是基于部分同步网络模型假定。我们也是基于部分同步网络模型假定来进行讨论。
BFT 共识协议#
概述#
一个分布式系统是由多个节点组成,节点之间需要网络发送消息通信,根据它们遵循的协议在某个任务消息达成共识并一致执行。这个过程中会出现很多类型的错误,但它们基本上可以分为两大类。
第一类错误是节点崩溃、网络故障、丢包等,这种错误类型的节点是没有恶意的,属于非拜占庭错误。
第二类错误是节点可能是恶意的,不遵守协议规则。例如验证者节点可以延迟或拒绝网络中的消息、领导者可以提出无效块、或者节点可以向不同的对等体发送不同的消息。在最坏的情况下,恶意节点可能会相互协作。这些被称为拜占庭错误。
考虑到这两种错误,我们希望系统始终能够保持两个属性:安全性(safety)和活跃性(liveness)。
- 安全性:在以上两类错误发生时,共识系统不能产生错误的结果。在区块链的语义下,指的是不会产生双重花费和分叉。
- 活跃性:系统一直能持续产生提交,在区块链的语义下,指的是共识会持续进行,不会卡住。假如一个区块链系统的共识卡在了某个高度,那么新的交易是没有回应的,也就是不满足 liveness。
BFT(拜占庭容错协议)是一种即使系统中存在恶意节点也能保证分布式系统的安全性和活跃性的协议。根据 Lamport[2]的经典论文,所有 BFT 协议都有一个基本假设:节点总数大于 3f 时,恶意节点最大为 f ,诚实节点可以达成一致的正确结果。
PBFT#
实用拜占庭容错算法(PBFT[3])是现实世界里首批能够同时处理第一类和第二类错误的拜占庭容错协议之一,基于部分同步模型,解决了之前 BFT 类算法效率不高的问题,将算法复杂度由节点数的指数级降低到节点数的平方级,使得拜占庭容错算法在实际系统应用中变得可行。
目前区块链中使用的 BFT 类共识协议都可以认为是 PBFT 的变形,与 PBFT 一脉相承。
正常流程#
PBFT 正常流程如下所示(图 1 中 C 为客户端,系统中有编号分别为 0 ~ 3 的四个节点,且节点 3 为拜占庭节点):
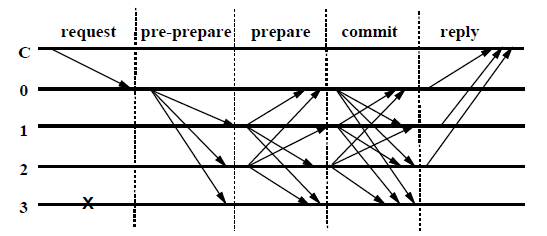
PBFT 正常流程为 3 阶段协议:
- pre-prepare:主节点(Primary)广播预准备消息(Preprepare)到各副本节点(Replica)
- prepare:该阶段是各个节点告诉其他节点我已经知道了这个消息,一旦某个节点收到了 包含 n-f 个 prepare 消息(我们将使用 QC 也就是 Quorum Certificate 来指代,下同)则进入 prepared 状态
- commit:该阶段是各个节点以及知道其他节点知道了这个消息,一旦某个节点收到了 n-f 个 commit 消息(QC)则进入 committed 状态
视图切换流程#
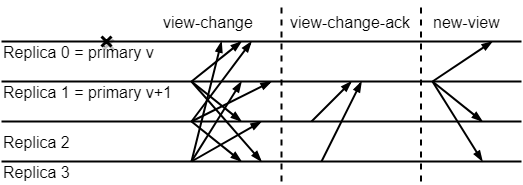
视图切换(viewchange)是 PBFT 最为关键的设计,当主节点挂了(超时无响应)或者副本节点集体认为主节点是问题节点时,就会触发 ViewChange 事件,开始 viewchange 阶段。此时,系统中的节点会广播视图切换请求,当某个节点收到足够多的视图切换请求后会发送视图切换确认给新的主节点。当新的主节点收到足够多的视图切换确认后开始下一视图,每个视图切换请求都要包含该节点达到 prepared 状态序号的消息。
在视图切换过程中,我们需要确保提交的消息序号在整个视图更改中也是一致的。简单来说,当一个消息定序为 n,且收到 2f+1 个 prepare 消息之后,在下个视图中,依然会被分配序号为 n,并重新开始正常流程。
通信复杂度问题#
PBFT 是基于三阶段投票即可达成共识的协议。prepare 和 commit 阶段中,都需要每个节点广播自己的 prepare 或 commit 消息,因此通信复杂度是$O(n^2)$。
view change 过程中,需要所有的副本节点先 time out,然后对于 view change 这件事达成共识,然后,他们把这个共识(以及已经达成了共识这件事)告诉新的主节点,新的主节点还要把这个消息广播出去宣布 view change,因此,view change 的通信复杂度是$O(n^3)$。
高达 $O(n^3)$ 的通信复杂度无疑给 PBFT 的共识效率带来了严重的影响,极大地制约了 PBFT 的可扩展性。
BFT 协议的优化#
如何把$O(n^3)$的通信复杂度降到$O(n)$,提高共识效率,是 BFT 共识协议在区块链场景中面临的挑战。针对 BFT 共识效率的优化方法,具有以下几类:
聚合签名#
E.Kokoris-Kogias 等在其论文中提出了在共识机制中使用聚合签名的方法。论文中提到的ByzCoin[4]以数字签名方式替代原有 PBFT 使用的 MAC 将通信延迟从$O(n^2)$降低至$O(n)$,使用聚合签名方式将通信复杂度进一步降低至$O(logn)$。但 ByzCoin 在主节点作恶或 33%容错等方面仍有局限。
之后一些公链项目,例如Zilliqa[5]等基于这种思想,采用 EC-Schnorr 多签算法提高 PBFT 过程中 Prepare 和 Commit 阶段的消息传递效率。
通信机制优化#
PBFT 使用多对多(all-to-all)的消息模式,因此需要 $O(n)$ 的通信复杂度。
SBFT(Scale optimized PBFT)[6]提出了一个使用收集器(collector)的线性通信模式。这种模式下不再将消息发给每一个副本节点,而是发给收集器,然后再由收集器广播给所有副本节点,同时通过使用门限签名(threshold signatures)可以将消息长度从线性降低到常数,从而总的开销降低到$O(n)$。
Tendermint[7]使用 gossip 通信机制,乐观情况下可以将通信复杂度降低到$O(nlogn)$。
view-change 流程优化#
所有的 BFT 协议都通过 view-change 来更换主节点。PBFT,SBFT 等协议具有独立的 view-change 流程,当主节点出问题后才触发。而在 Tendermint、HostStuff[8]等协议中没有显式的 view-change 流程,view-change 流程合入正常流程中,因此提高了 view-change 的效率,将 view-change 的通信复杂度降低。
Tendermint 将 roundchange(和 viewchange 类似)合入正常流程中,因此 roundchange 和正常的区块消息 commit 流程一样,不像 PBFT 一样有单独的 viewchange 流程,因此通信复杂度也就降为$O(n^2)$。
HotStuff 参考 Tendermint,也将视图切换流程和正常流程进行合并,即不再有单独的视图切换流程。通过引入二阶段投票锁定区块,并采用 leader 节点集合 BLS 聚合签名的方式,将视图切换的通信复杂度降低到了$O(n)$。
链式 BFT#
传统 BFT 需要对每个区块进行两轮共识,$O(n)$的通信复杂度可以让区块达到 prepareQC,但是必须要$O(n^2)$ 的通信复杂度才能让区块达到 commitQC。
Hotstuff 将传统 BFT 的两轮的同步 BFT 改为三轮的链式 BFT,没有明确的 prepare,commit 共识阶段,每个区块只需要进行一轮 QC,后一个区块的 prepare 阶段为前一个区块的 pre-commit 阶段,后一个区块的 pre-commit 阶段为前一个区块的 commit 阶段。每次出块的时候都只需要$O(n)$的通信复杂度,通过两轮的$O(n)$通信复杂度,达到了之前$O(n^2)$的效果。
流水线(Pipelining)和并行处理(Concurrency)#
PBFT、Tendermint 等协议具有即时确定(Instant Finality)的特性,几乎不可能出现分叉。在 PBFT 中,每个区块被确认后才能出下一个区块,Tendermint 还提出区块锁定的概念,进一步确保了区块的即时确定性,即在某个 round 阶段,节点对区块消息投了 pre-commit 票,则在下一个 round 中,该节点也只能给该区块消息投 pre-commit 票,除非收到新 proposer 的针对某个区块消息的解锁证明。
这类 BFT 共识协议本质上是一个同步系统,将区块的生产和确认紧密耦合,一个区块确认后才能生产下一个区块,需要在块与块间等待最大的可能网络延迟,共识效率受到很大的限制。
HotStuff 的 Pipelining 方法将区块的生产和确认分离,每个区块的最终确认需要后两个区块达到 QC,也就意味着上一个区块没有完全确认(需要满足 Three-Chain)的情况下可以生产下一个区块。这种方式实际上还是一个半同步系统,每个区块的产生还是需要等上一个区块达到 QC。
EOS[9]的 BFT-DPoS 共识协议可认为是一种完全并行的 Pipelining 方案:每个区块生产后立即全网广播,区块生产者一边等待 0.5 秒生产下一个区块,一边接收其他见证人对于上一个区块的确认结果,使用 BFT 协议达成共识,新区块的生产和旧区块确认的接收同时进行,这极大地优化了出块效率。
CBFT 共识协议#
为什么设计 CBFT#
前面的内容中,我们分析了 BFT 共识协议的问题,以及几种主流的优化 BFT 共识协议,这些 BFT 共识协议在降低通信复杂度和出块效率方面都取得了不错的研究成果,但仍存在一些改进空间。
PBFT 较之于之前的 BFT 算法虽更实用,但因受制于 O(n^(3))的视图切换开销,在扩展性方面存在很大的问题。
Tendermint 将 round change 和正常流程合并,简化了视图切换逻辑,将视图切换的通信复杂度降低为$O(n^2)$,但需要等待一个比较大的网络时延来保证活跃性。同时 Tendermint 仍然是串行出块和确认,一个区块的投票需要等上一个区块 commit 完成才能开始。
EOS 的 BFT-DPOS 共识协议中,区块生产者可以连续产生若干区块,同时区块采用并行确认,提高了出块速度。使用 BFT 协议确认出块,但仅适用于强同步的通信模型。
HotStuff 创新地提出了基于 leader 节点的、三阶段提交的 BFT 共识协议,吸收了 Tendermint 的优点,将 viewchange 和正常流程合并,并将 viewchange 的通信复杂度降至线性。同时通过简化消息类型,可以 pipeline 的方式确认区块。但引入了新的投票阶段也会增加通信复杂度,同时一个视图窗口只确认一个区块,这无疑需要耗费较多的通信复杂度在视图切换上。此外,基于 Leader 节点收集投票的星状拓扑结构,比较适合于 Libra 这种网络环境良好的联盟链,在弱网环境中比较容易受单点故障影响,造成较大的 leader 节点切换开销。
因此,我们提出了 CBFT 共识协议,在以上共识协议的基础上进行进一步的优化,可以极大地降低通信复杂度 ,并且提高出块效率。
CBFT 概述#
CBFT 基于部分同步网状通信模型,提出了一个三阶段共识的并行拜占庭容错协议。网状的通信模型更适合公网的弱网环境,在 Alaya 上已经使用了该协议作为共识算法。
CBFT 的正常流程和 Hotstuff 类似,分为 prepare,pre-comit,commit 和 decide 几个阶段。但 CBFT 还作了关键的改进:在一个视图窗口内可以连续提议多个区块,下一个区块的产生不用等上一个区块达到 QC;而且各个节点可以在接收上一个区块投票的同时,并行执行下个区块的交易,以 pipeline 的方式对区块进行投票确认, 从而极大提高了出块速度。
CBFT 有自适配的视图切换机制:在一个视图窗口内,节点接收到足够多的区块以及赞成票(超过 2/3 的节点投票,也就是 QC)时,会自动进行窗口切换,切换到下一个窗口,无需进行 viewchange 投票。除此之外,节点才会启动 viewchange 流程,并且在 viewchange 阶段引入了和 Hotstuff 一样的二阶段锁定投票规则,同时使用 BLS 聚合签名,可以在$O(n^2)$的通信复杂度内完成视图窗口切换。
根据上面的讨论,CBFT 只在正常流程之外才会进行 viewchange,因此相比 HotStuff 会有更少的视图切换开销。
接下来先给出 CBFT 共识中涉及的相关概念及其含义说明,便于之后对 CBFT 进行详细介绍。
CBFT 相关术语#
- 提议人(Proposer): CBFT 共识中负责出块的节点
- T: 时间窗口,每个提议人只能在自己的时间窗口进行出块
- N: 共识节点总数
- f: 拜占庭节点最大数量
- 足够多赞成票: 表示为至少收到 N-f 张赞成票
- 验证人(Validator): 共识节点中非提议人节点
- 视图(View): 当前提议人的时间窗口可以产生区块的时间范围
- ViewNumber: 每个时间窗口的序号,随着时间窗口递增
- HighestQCBlock: 本地最高的 N-f PrepareVote 区块
- ProposalIndex: 提议人的索引号
- ValidatorIndex: 验证人的索引号
- PrepareBlock: 提议的区块消息,主要包含区块(Block),提议人索引号
- PrepareVote: 验证人对提议区块的 Prepare 投票,每个验证人需要执行区块后才发送 PrepareVote。主要包含 ViewNumber, 区块 hash, 区块高度,验证人索引号(ValidatorIndex)
- ViewChange: 当时间窗口超时,提议人的区块没有都收集到 N-f PrepareVote,则会向下一个提议人发送 ViewChange。ViewChange 包含 提议人索引号(ValidatorIndex),最高确认区块(HighestQCBlock)
- 锁(Lock): 对指定块高进行锁定
- Timeout: 超时(时间窗口到期可以看作提议人的超时时间)
- 法定: 最大被允许
- 同一个 View: 两个 View 的 ViewNumber 相等,可以成为同一个 View
BLS 签名#
目前业界采用的聚合签名方案主要是 BLS 聚合签名。BLS 聚合签名是在 BLS 签名方案基础上的扩展方案。Boneh-Lynn-Shacham(BLS)签名方案是 Dan Boneh,Ben Lynn, Hovav Shacham[10]于 2001 年提出的。BLS 签名目前在许多区块链项目如 Dfifinity、fifilecoin、 Libra 中都得到了运用。 BLS 聚合签名可以把多个签名简化为 1 个聚合签名,对于提高 BFT 共识协议中的通信效率至关重要。
值得注意的是,BLS 聚合签名的方法是有漏洞的。一种称为 rogue public key 的攻击可以使得攻击者有机会在获得其他签名者的公钥和标准 BLS 签名信息之后,能够操纵聚合签名的输出结果。
对这个攻击的一种最直接的防御措施是,参与 BLS 聚合签名的人都需要先证明各自确实掌握了 BLS 私钥信息,并事先注册。这一过程可以通过使用一种简单高效的零知识证明技术(Schnorr 非交互式零知识证明协议)完成。参与者在进行聚合签名之前,需要给出零知识证明,证明其持有公钥信息的同时,确实掌握了该公钥对应的私钥信息。
CBFT 协议流程#
正常流程#
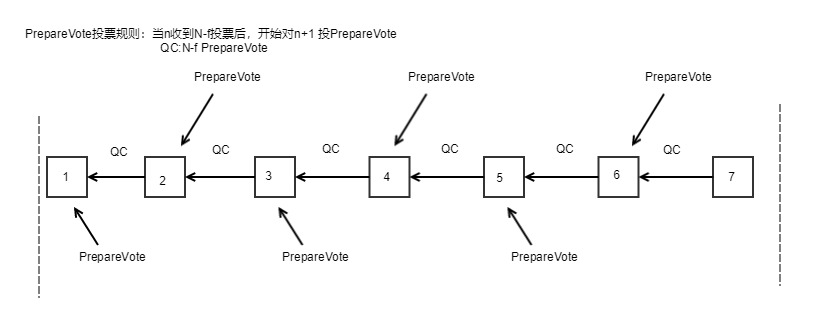
逐个验证区块:验证人校验签名和时间窗口,执行区块,成功后产生 PrepareVote<ViewNumber,BlockHash, BlockNumber>。当 PrepareVote 对应的父区块收集到 N-f 个 PrepareVote 时,使用 BLS 将 N-f 个 PrepareVote 的个体签名聚合成一个聚合签名,并将当前 PrepareVote 进行广播。我们将 N-f 个 PrepareVote 简化为 prepareQC(quorum certificate) 。
当节点在当前 view 内最后一个区块收到 prepareQC,则会进入新的 view 开始下一轮投票。
为了更安全的投票,投票必须符合以下规则:
区块执行后才能进行投票
诚实的节点只能对当前 View 提议的区块进行投票
诚实的节点当 View 超时后不能再进行投票,也不接收当前 View 的投票
在同一个 View 内,相同高度的两个区块只能投其中一个
当对 Block(n+1)进行投票时,Block(n)需达到 prepareQC
ViewChange 流程#
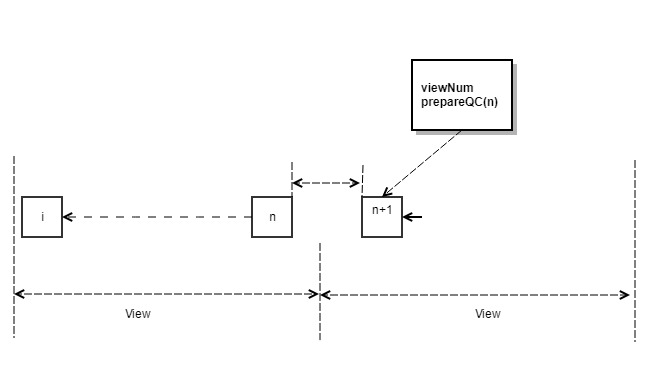
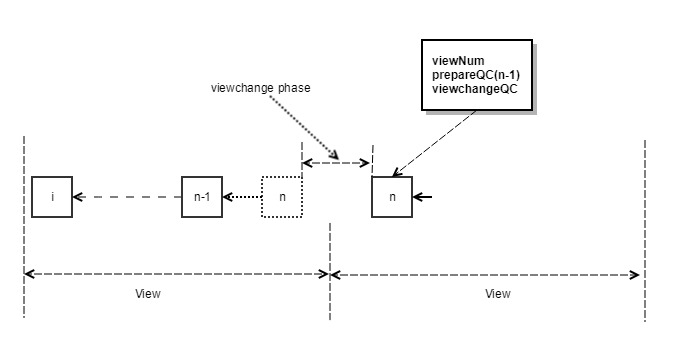
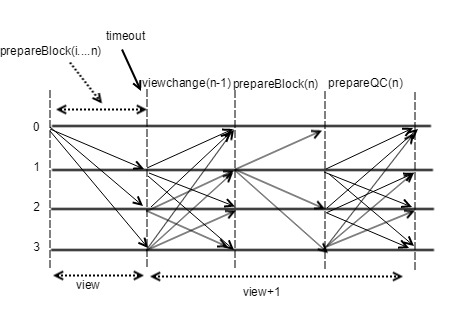
- 如果在时间窗口内,收到第 n 块的 prepareQC,则更新本地 view+1,进入新的正常流程,这种情况下如果是新提议人达成 n 的 QC,则开始广播第一个区块,如图 4 所示,高度为 BlockNumber(n)+1 ,并会携带 n 区块的 prepareQC。
- 如果时间窗口过期,节点首先会拒绝对当前提议人的区块产生新的投票,同时没有收到第 n 块的 prepareQC,则发送 ViewChange<ViewNumber, HighestQCBlock>消息,如图 5 所示。
- 下一个时间窗口的提议人收到 N-f 个 ViewChange 消息(我们将 N-f 个 ViewChange 消息简称为 viewchangeQC )之后,使用 BLS 签名聚合成一个 QC 签名,然后更新本地 ViewNumber+1,由于采用两轮投票锁定区块的规则,新提议人可以简单地从收到的 N-f 个 viewchange 消息中选择 HighestQCBlock,将新的区块序号定为 HighestQCBlock+1,如图 6 所示,然后广播第一个区块给各验证人节点,并携带 HighestQCBlock 的 QC 签名和 viewchange 的 QC 签名。
- 各验证人节点会根据收到的 HighestQCBlock+1 序号开始新一轮共识。
区块确认#
Pipelining 流程#
在传统 BFT(PBFT, Tendermint)中,每个区块通常都需要经历明确的 Pre-Commit 和 Commit 阶段才最终确认:
- Pre-Commit: 当节点收到 N-f 个 Prepare 投票时会广播 Pre-Commit, Pre-Commit 可以看作对 Prepare 阶段的确认。
- Commit: 当收到 N-f 个 Pre-Commit 投票时,表明所有节点对指定消息达成一致,提交到本地磁盘。
根据上面的介绍,CBFT 中也有类似的 Prepare 和 ViewChange 两个阶段,每个区块只有 Prepare 投票,没有明确的 Pre-Commit 和 Commit 阶段,那么如何达到区块的确认呢?CBFT 可看作 Pipeline 版本的 BFT,每个 prepareQC 都是对前面区块更高阶段的确认。
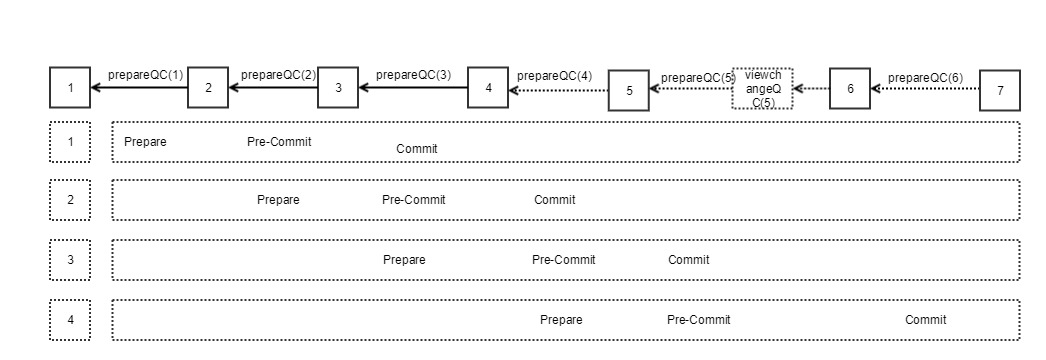
因此在 CBFT 中,只有两种消息类型:prepare 消息和 view-change 消息,每个消息的 QC 均采用聚合签名方式验证。
区块重组#
假设每个 view 允许产生 n 个区块,当前 view $V_i$ 时间窗口超时,view 切换到$V_{i+1}$,此时$V_i$产生的区块只有部分得到 QC,部分区块会进行重组,重组规则如下:
- Pre-Commit 状态的区块被锁定,不能被重组,即如果当前节点在高度 h 上有 Pre-Commit 状态的区块,当前节点不能在高度 h 产生新的区块,也不能在高度 h 对其他区块投票
- Prepare 状态的区块可以被重组,即如果当前节点在高度 h 上有 Prepare 状态的区块,当前节点可以在高度 h 产生新的区块,或者在高度 h 对其他区块投票(只允许对更高 viewnumber 的区块投票)
验证人替换机制#
CBFT 共识中,每 250 个区块(称为一个 Epoch)就会更新验证人集合,更新规则如下:
- 新验证人可能由于网络连接或区块不同步等原因不能参与共识,因此我们每次替换不超过 8 个节点,如果候选验证人不足 8 个,替换的数量为候选验证人的总数。
- 使用 VRF 从候选验证人中随机选出新验证人。
容错恢复(WAL)机制#
CBFT 共识提供了容错恢复机制,也就是 WAL 模块。该模块不属于严格意义上的预写日志系统,但是借鉴了相关思想,在验证人共识过程中将还未落链区块的共识状态和当前 View 的共识消息从内存分别持久化到本地数据库和本地文件。在系统 crash 或者机器掉电重启之后通过磁盘日志数据迅速恢复共识状态。
这里简要介绍一下主要的原理:
- 区块、viewChange 在各验证人间达成共识需要经历验证、投票等阶段,某个区块最终落链前与该区块相关的共识状态、消息都记录在内存中。节点重启也只是需要恢复这部分还未落链区块的内存数据,因此 checkpoint 恢复点也就是当前 blockchain 的 currentBlock
- 链式投票可得,每一区块的投票都是对前一区块的确认,达到第三级,即达到区块的 Commit 阶段,因此 3-chain 区块的 prepareQC 状态在共识中至关重要,必须保证在重启后恢复,这部分数据存储至 db
- 共识消息只保留最近一轮 view 相关的,这部分数据存储至文件
区块同步机制#
由于 CBFT 共识的异步并行性,导致最新的区块存储在内存中,并且区块高度有 3 种高度:最高逻辑区块高度、最高确认区块高度和写入磁盘区块高度,并且三种高度依次递减。因此 CBFT 中的区块同步机制也在已有的 Alaya-P2P 的基础上作了适配,调整了区块高度的获取方式。 这里概要介绍区块同步机制如下:
- 新加入节点通过 Alaya-P2P 利用快速同步或全同步更新至主网高度
- 共识节点利用 CBFT-P2P 的心跳机制与其它节点保持块高一致
- 共识节点区块落后时,会主动减少通信量,全力处理区块同步
- 同步机制使用 BLS 签名来减少网络同步消息量
CBFT 分析#
基本规则定义#
为方便对 CBFT 的安全性和活跃性进行分析 ,我们定义 CBFT 的几条基本规则。
K-Chain 规则#
对于一条链,满足以下条件:
B(0)<-C(0)<-...<-B(k-1)<-C(k-1)
我们将其定义为 K-Chain, 其中 B 为 Block, C 为 B 的 prepareQC。我们可以看到当达到 3-Chain 时如:B0<-C0<-B1<-C1<-B2<-C2, B0 达到 Commit 状态。
Lock-Block 规则#
节点 a 中, 当区块 n 收到区块 n 之后的 2 次 prepareQC,则区块 n 定义为 Lock-Block(a)。可以观察到,当 Lock-Block(a) = B0 时,B0 达到 2-Chain, 如B0<-C0<-B1<-C1。
Unlock-Block 规则#
假设 Lock-Block(a)为 n,当 n 的子区块 n+1 达到 2 次 prepareQC,则 Lock-Block(a)为 n+1。可以观察到,当 Lock-Block(a) = B0 时,B0 达到 2-Chain, 如 B0<-C0<-B1<-C1-B2,当 B0 Unlock-Block 时,B0 达到 3-Chain,如B0<-C0<-B1<-C1<-B2<-C2。
Previous-Block 规则#
形如 Block(B)<-prepareQC(B)<-Block(B'),我们将 Block(B)定义为 Block(B')的 Previous-Block, 则可表示为 Previous-Block(B') = Block(B)。
由 Lock-Block 与 Previous-Block 规则可知:
在节点 a 中,形如 B<-C<-B'<-C'<-B'' , Previous-Block(B'') > Lock-Block(a)
Commit 规则#
当区块 n, 收到区块 n 之后的 3 次 prepareQC,则区块 n 被 Commit。可以观察到,当 B0 被 Commit 时,B0 达到 3-Chain,如 B0<-C0<-B1<-C1<-B2<-C2。
安全性(safety)证明#
1) 不存在同一个 View 中有两个相同高度区块都能收到足够多投票
证明: 假设 N=3f+1 为节点总数,f 为拜占庭节点最大数量,那么当收到 2f+1 投票为足够多投票。因两个区块都收到至少 2f+1,投票总量至少为 2(2f+1) = N+f+1, 可以看到至少有 f+1 对两个区块投了票,与 f 个拜占庭节点假设矛盾。
2) 对于 3-Chain 来说,B0<-C0<-B1<-C1<-B2<-C2, ViewNumber(B2) >= ViewNumber(B0)。那么存在 Block(B),当 ViewNumber(B) > ViewNumber(B2),则 Previous_Block(B) > B0。
证明: 对于正常诚实节点(给区块 B2,B 投过票)来说, 那么节点至少可以看到 B0<-C0<-B1<-C1<-B2, 也就是 Lock-Block 最小为 Lock-Block(B0)。因为 ViewNumber(B) > ViewNumber(B2),则根据 ViewChange 确认规则,ViewNumber(B)的第一个区块不小于 B1,则 Previous_Block(B) > B0
3) 假设节点 n 的 Lock-Block(n) = B,节点 m 的 Lock-Block(m) = B',如果 Number(B) = Number(B'), 则 Hash(B) = Hash(B')
证明: 由上面 Lock-Block 规则可知,存在 2 种 Lock-Block 场景,第一种情况两个 QC 在同一 View 内,则由 1 可知不存在 B'和 B 同时收到足够多投票。第二种情况,出现 B 与 B'分属不同 View,且都收到 prepareQC(B), prepareQC(B')。假设 ViewNumber(B') > ViewNumber(B), 那么根据结论 2,Previous_Block(B') > B,与假设矛盾。
4) 在 Commit 阶段不会有两个相同高度不同块 Hash 被 Commit
证明: 由 3 可知,如果 Number(B) = Number(B'),不存在 B,B''同时被 Lock-Block。则可推不存在 Commit(B),Commit(B')都被提交。
活跃性(liveness)证明#
假设节点间网络最大延时为 T,执行区块为 S
1) 不存在时间窗口永远小于 time(prepareQC)*2 时间
证明: 根据实际网络状况,合理调整实际窗口大小,可以保证时间窗口内至少达成 2 次 QC,则时间窗口至少为 2S+4T
2) ViewNumber 可以达成一致,并且递增
证明: ViewChange 达成一致最少需要 T,由结论 1 可以保证 ViewChange 可以达成一致,为那么 ViewNumber 可以进行递增切换
3) Lock-Block 高度永远递增
证明: 假设 ViewNumber 为 n, n+1, 由安全证明(2),可以保证 ViewNumber(n+1)的第一个区块 Previous-Block 至少为 Lock-Block(View(n)),又由于活证明(1), 至少有两次 prepareQC,可以得到两个 View 锁定高度的关系,Lock-Block(View(n+1)) >= Lock-Block(View(n))+1
通信复杂度分析#
- PBFT: 网状网络拓扑,采用二阶段投票协议,消息达到 prepared 状态即锁定,有单独的视图切换流程,正常流程通信复杂度为$O(n^2)$,视图切换流程通信复杂度为$O(n^3)$。
- Tendermint: 网状网络拓扑,采用二阶段投票协议, 消息达到 prepared 状态即锁定,视图切换流程和正常流程合并,通信复杂度为$O(n^2)$。
- Hotstuff 星状网络拓扑,采用三阶段投票协议,消息达到 pre-commited 状态即锁定,视图切换流程和正常流程合并, 通信复杂度为$O(n)$。
- CBFT: 网状网络拓扑,采用三阶段投票协议, 消息达到 pre-commited 状态即锁定, 自适配视图切换流程, 通信复杂度为$O(n^2)$。
回顾与总结#
本文讨论了目前常见的 BFT 类共识算法,提出了一种可以更适合公网环境的 CBFT 协议,可以在满足安全性和活跃性的前提下,大大提高区块出块确认速度,满足区块链当下越来越高的共识速度需求。
参考文献#
[1] M. J. Fischer, N. A. Lynch, and M. S. Paterson, “Impossibility of distributed consensus with one faulty process,”J. ACM, 1985.
[2] L. Lamport, R. Shostak, and M. Pease. The Byzantine Generals Problem. ACM Transactions on Programming Languages and Systems, 4(3), 1982.
[3] M. Castro and B. Liskov. Practical byzantine fault tolerance. In OSDI,1999.
[4] E. Kokoris-Kogias, P. Jovanovic, N. Gailly, I. Khoffi, L. Gasser, and B. Ford, “Enhancing Bitcoin Security and Performance with Strong Consistency via Collective Signing,” 2016.
[5] TEAM T Z. Zilliqa TechnicalWhitepaper[J]. Zilliqa, 2017: 1–8.
[6] Guy Golan Gueta, Ittai Abraham, Shelly Grossman, Dahlia Malkhi, Benny Pinkas, Michael K. Reiter, Dragos-Adrian Seredinschi, Orr Tamir, Alin Tomescu,“a Scalable and Decentralized Trust Infrastructure”,2018.
[7] C. Unchained, “Tendermint Explained — Bringing BFT-based PoS to the Public Blockchain Domain.” [Online]. Available: https://blog.cosmos.network/tendermint-explained-bringing-bft-based-pos-to-the-public-blockchain-domain-f22e274a0fdb.
[8] M. Yin, D. Malkhi, M. K. Reiterand, G. G. Gueta, and I. Abraham, “HotStuff: BFT consensus in the lens of blockchain,” 2019.
[9] “EOS.IO Technical White Paper v2.” [Online]. Available: https://github.com/EOSIO/Documentation/blob/master/TechnicalWhitePaper.md.
[10] Dan Boneh, Manu Drijvers, Gregory Neven. "BLS Multi-Signatures With Public-Key Aggregation", 2018.